上一篇中,我们笼统的讲解了Sphinx/Coreseek的实时索引,文章发表后,我突然意识到,我们对于Sphinx/Coreseek的认识还非常不足,如果您是第一次接触Sphinx/Coreseek,或许前一篇文章对您来说非常要命。因此我们本文还需要介绍更多关于Sphinx/Coreseek的内容。
本文中,我们将介绍:
(1)、Sphinx/Coreseek组件以及常用命令
(2)、多索引的设置
(3)、Sphinx/Coreseek词库设置
(4)、Sphinx/Coreseek停词设置
(5)、SphinxClient的使用
一、Sphinx/Coreseek组件以及常用命令
目前Sphinx/Coreseek主要有这么几个重要的执行组件,它们就位于bin目录下,它们分别为“search”、“indexer”、“searchd”。下面就让我为各位读者对这几个“核心”的工具进行逐一的讲解。
Search:正如它的名字一样“搜索”,而事实上这个Search是集“搜索”、“拆词拆句”于一身的工具,它使用的方式也比较简单,就是“路径/search '语句'”
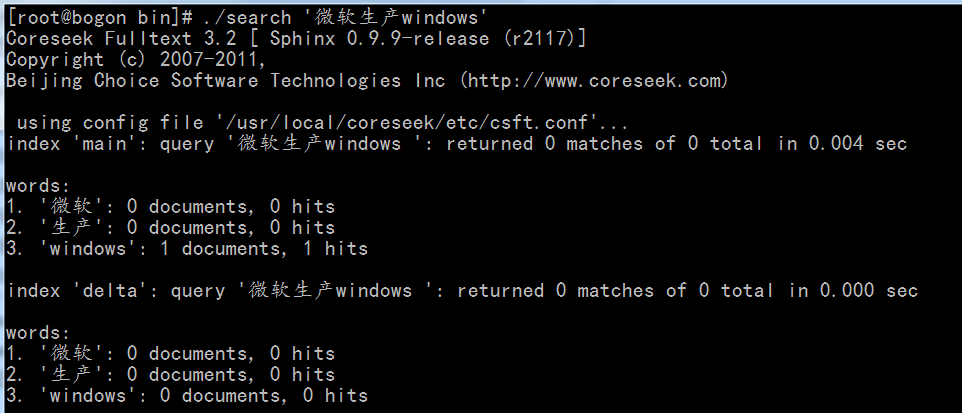
可以看到它返回了一堆的结果,我们根据这个结果获取到一些信息,譬如它把这个句子切割成什么词汇,每个词汇命中了多少个文档,总共命中了多少次,从哪个索引命中等。
这里值得一提的就是:请确认你的MYSQL(或者其他,看你的config配置为什么数据库了)事先开启并连接正常,否则将提示错误。

indexer:同样作为Sphinx/Coreseek的核心组件,它的作用是根据配置文件中预设的数据源构建相应的索引。它的使用比较灵活,主要有以下几个参数:
--all:这个参数用于重新构建所有的索引。
--quiet:加了这个参数后,除非程序出现了错误,否则不输出任何构建信息
--rotate:当searchd已经启动时,任何构建索引都需要添加此参数(关于searchd后面会介绍)
--buildstops:重新设置停词(这只是个临时性的方法,后面会介绍更彻底的方法)
--merge:合并索引(不过在上一篇中,我们采用了重新构建而非合并)
直接索引名:您也可以直接加索引名的方式,Sphinx/Coreseek将只对该索引进行重新构建
searchd:如果需要Sphinx/Coreseek以服务形式提供服务,则使用此组件,使用方法比较简单,直接运行即可,searchd会自动的引用config中配置的一些策略,默认监听9312端口。如果要停止服务的话,也只需加“--stop”参数即可。与search相同,请确保您的数据库服务已经开启。
二、多索引设置
经过上文,我们已经知道Sphinx/Coreseek是可以设置多个索引的。而事实上我们也对此有需求,这种需求除了可以做实时索引还可以根据不同的业务做不同的索引。同样的,从上文中,我相信各位读者大概也了解它大致的配置方式,我这里再重复一遍,讲一下配置方式以及注意事项。
一般来说,source节点和index节点是一一对应的,添加一个索引就意味这添加一组的source/index节点即可。
添加新的索引后,各位读者可以选择自行的添加新的配置项(拷贝复制的方式),也可以采用像“继承”的方式,把“父”配置继承过来,但这里需要小心的一点,那就是有些“专有”配置(譬如查询语句等)需要在“子”节点中进行覆盖或重设,方法也比较简单,只需在“子”节点中重设下相应的配置项即可。
三、Sphinx/Coreseek词库设置
句子是由不同的词汇拼接而成,而全文索引也是使用同样的原理,根据预设的词库把一个句子拆分成不同的词汇,然后再保存起来。当用户需要搜索时,Sphinx/Coreseek再根据词汇进行检索。
在设置词汇之前,我们先看看Sphinx/Coreseek把“机智的小蝶惊鸿”的拆分情况。
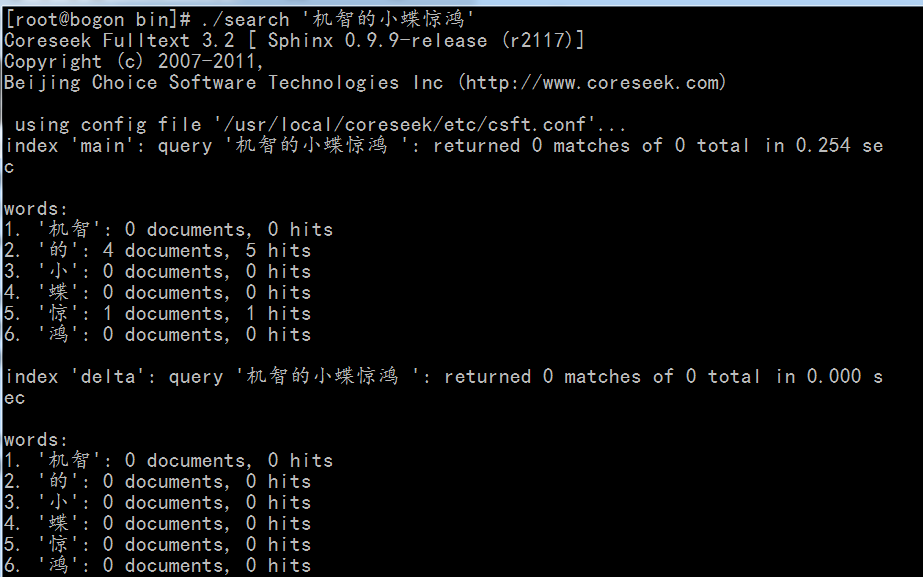
由于上文的原因,我们设置了两个索引,因此出现了两个结果集。忽略这个内容,我们取其一。Sphinx/Coreseek把这一句话划分为“机智”、“的”、“小”、“碟”、“惊”、“鸿”这么几个词,总的来说基本上划分是正确的,但这里存在一个问题,那就是“小蝶惊鸿”其实是一个词,一个特殊的/专有名词,Sphinx/Coreseek并不认识它,因此我们需要手动的把这个专有名词添加进它的词库中。
Sphinx/Coreseek设置词库的方法异常简单,由于我们已经配置好了词库的位置,因此我们只需修改词库即可。
我们先切换到“mmseg”的etc目录(/usr/local/mmseg3/etc),然后用vi打开“ unigram.txt”。可以看到里面已经预设了一堆的词组,具体内容我就不详讲了,我们翻到最后一行,然后加入我们的词组。
具体格式是:“词组 1”,然后在下一行再添加一个“x:1”,这里注意一点,词组和1之间使用的是\t(Tab键)而非空格!!!

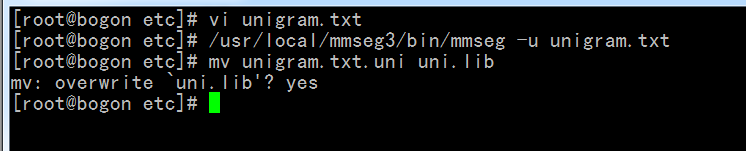
保存退出后再执行
/usr/local/mmseg3/bin/mmseg -u unigram.txt
然后执行
mv unigram.txt.uni uni.lib
便完成新字典的生成。
我们再重新试试刚才的分词操作:
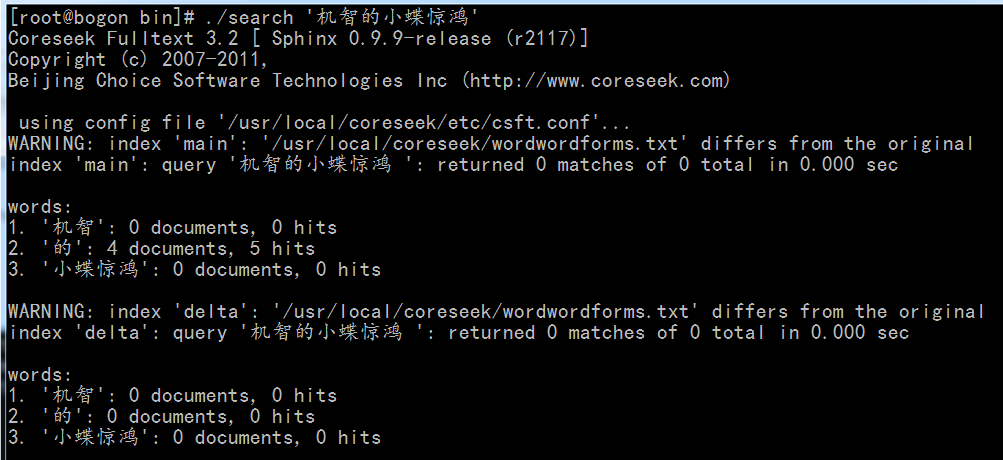
“小蝶惊鸿”已经作为一个专有名词成功划分!!这里我还要罗里吧嗦的说一句,那就是请小心您的编码集,一定要用utf8编码,否则会失败的!
四、Sphinx/Coreseek停词设置
正如上一节中所述,句子由不同的词汇拼接而成,而拼接这些词汇需要一个“胶水”,它们就是停词。停词是从stopword直接翻译过来的,主要包含了冠词、介词、副词和连词、语气词等,正如棒子语会在每句话后面加“思密达”一样,这些词语基本没有什么实际的意义,我们的全文索引也没必要收录这些词浪费不必要的性能(譬如上面的‘的’字)。
要设置停词,我们只需用vi打开Sphinx/Coreseek的配置文件,然后在index节点中添加
stopwords = /usr/local/coreseek/stopword.txt
这里我们添加到main节点,并设置停词文件位于“/usr/local/coreseek/stopword.txt”,而delta继承自main,同样也继承该配置。
再把“的”字添加到停词文件中,然后我们再试试:

可以发现“的”字已经不见了,停词设置成功!
五、SphinxClient的使用
好了,终于到了白热化的阶段,我们要讲讲怎么在程序中使用Sphinx/Coreseek的服务了,Sphinx/Coreseek中已经提供了几款的API(没有C#的),这里我额外自己利用私人的时间写了一份C#版的API。
目前改API在Microsoft.NET和Mono下均可用,采用APacheV2协议开源。
目前项目托管在同步托管在两个地方,它们分别是:
OSC:http://git.oschina.net/xiaodiejinghong/SphinxClient
Github:https://github.com/xiaodiejinghong/SphinxClient
里面已经自带源码和相关Example,使用非常简单,各位读者可以自行看看,还有疑问的读者可以联系我,我都会尽量帮忙。
此外,您还可以直接从Nuget中获取:
PM> Install-Package Jhong.SphinxClient
这里就不说太多了,Just do it。
好的Sphinx/Coreseek就大概讲到这里了,希望能够帮到各位读者。谢谢!
