上一篇中,我们已经介绍了怎么简单的对Sphinx/Coreseek进行配置,也已经尝试了对一些中文句子进行分词并搜索。接下来,我们将面临一个很重要也一定要遇到的问题,那就是实时性的问题。项目的运行必然伴随着数据的新增,如果没有外力的“干扰”,新增的数据是不会被Sphinx/Coreseek收录,用户也无法通过“索引器”查找到。如何把新增的数据收录进索引中,并且还要“实时”的收录成为了各位读者所必须面临的问题。或许有读者提议到,重新执行上文中“./indexer --all”生成索引。是的,使用这条命令确实可以把新增的数据加入到索引当中,虽然Sphinx/Coreseek生成索引的速度非常的快,但这也是非常呛的,难道就没有一种高效的方式能够让Sphinx/Coreseek以最优的方式得到实时索引?
令人庆幸的是,Sphinx/Coreseek早已经考虑到了这种情况,也给出了不错的解决方案,这就是我们本文中将要讲解的内容。本文中,我们将介绍:
(1)、实时索引的解决方案
(2)、配置Csft.Conf
(3)、实时索引执行策略
一、实时索引的解决方案
虽然在上文中,我们仅仅配置了一个名为“main”的数据源,但各位读者千万别误会,觉得Sphinx/Coreseek只能配置一个数据源。事实上,Sphinx/Coreseek是可以配置多个数据源的,哎!对的!可能有读者,特别是使用过全文索引的读者意识到,我们可以再配置多一个索引,这个索引每隔很短的一段时间执行一次,把近期所有新增的数据通通的收录到这个索引中。
没错,这也是我们Sphinx/Coreseek给出的实时索引解决方案,使用“主索引”+“增量索引”。使用这种方式作为实时索引的解决方案有以下的几个好处:
(1)、主索引无需频繁的进行重新生成操作(主索引数据量大)。
(2)、增量索引仅收录新增的数据,速度非常快(新增数据一般远小于累积数据)。
(3)、此组合的效果不错,已经能够胜任大部分的一般需求。
二、使用实时索引该如何配置
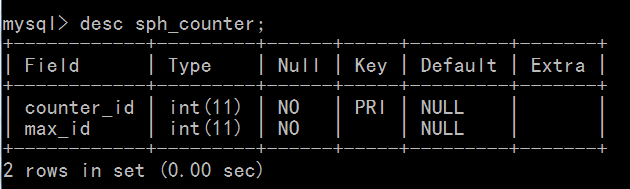
要配置实时索引,我们需要回到我们的配置文件(csft.conf)。在上文中,我们配置了一个索引为“main”的索引,它将作为主索引存在,接下来我们还需要再配置一个名为“delta”的索引,它将作为我们的增量索引。要配置实时索引,我们需要在数据库中建立一个表,它用来保存最新索引ID。其表结构如下:
然后我们先对“main”数据源(source)做一下小改动:
·在“sql_query_pre”下增加一行:“sql_query_pre = replace sph_counter (counter_id,max_id)values(1,(select max(id) from post))”
·把“sql_query”改为:“select id,title from post where id <= (select max_id from sph_counter where counter_id = 1)”
然后我们还需要增加一个“delta”的增量数据源:
·在“main”下增加一个“delta”,并让它继承自“main”(不明白的读者可以看演示)
·在“delta”中加入“sql_query_pre = SET NAMES utf8”
·在“delta”中加入“ sql_query = select id,title from post where id > (select max_id from sph_counter where counter_id = 1)”
我们还需要加入一个“delta”的索引配置:
·在“main”下增加一个delta,并让它继承自“main”(这里是index了,不是source)
·在“delta”中加入“source = delta”
·在“delta”中加入“path = /usr/local/coreseek/var/data/delta”
就这样,完成了增量索引的配置,完成的配置如下面的实例代码:
 配置好的csft.conf
配置好的csft.conf


1 # 2 # Minimal Sphinx configuration sample (clean, simple, functional) 3 # 4 5 source main 6 { 7 type = mysql 8 9 sql_host = localhost 10 sql_user = root 11 sql_pass = root 12 sql_db = blog 13 sql_port = 3306 # optional, default is 3306 14 15 sql_query_pre = SET NAMES utf8 16 sql_query_pre = replace sph_counter (counter_id,max_id)values(1,(select max(id) from post)) 17 sql_query = select id,title from post where id <= (select max_id from sph_counter where counter_id = 1) 18 19 # sql_attr_uint = group_id 20 # sql_attr_timestamp = date_added 21 22 sql_query_info = select id,title from post where id=$id 23 } 24 25 source delta:main 26 { 27 sql_query_pre = SET NAMES utf8 28 sql_query = select id,title from post where id > (select max_id from sph_counter where counter_id = 1) 29 } 30 31 index main 32 { 33 source = main 34 path = /usr/local/coreseek/var/data/main 35 docinfo = extern 36 charset_dictpath = /usr/local/mmseg3/etc/ 37 charset_type = zh_cn.utf-8 38 ngram_len = 0 39 } 40 41 index delta:main 42 { 43 source = delta 44 path = /usr/local/coreseek/var/data/delta 45 } 46 47 48 indexer 49 { 50 mem_limit = 32M 51 } 52 53 54 searchd 55 { 56 port = 9312 57 log = /usr/local/coreseek/var/log/searchd.log 58 query_log = /usr/local/coreseek/var/log/query.log 59 read_timeout = 5 60 max_children = 30 61 pid_file = /usr/local/coreseek/var/log/searchd.pid 62 max_matches = 1000 63 seamless_rotate = 1 64 preopen_indexes = 0 65 unlink_old = 1 66 } 67
解析一下上面配置的技巧策略:
(1)、因为构建索引时,索引器是可以带参数执行,指定只构建某个索引,因此我们可以指明只重构增量索引,不需将主索引重新构建。
(2)、数据库新增的表是为了区分主索引和增量索引的区间的,正如配置中所示,所有小于等于max_id的数据归属与主索引,大于的归属于增量索引。
(3)、delta:main的意思是继承配置,也就是使delta的配置与main一样。
(4)、重新插入sql_query是为了把从main中继承来的sql_query覆盖掉,避免执行了replace那一句
接下来我们可以重新执行“./indexer --all”重新生成索引。这里值得注意的一点,那就是,如果您已经启动了searchd,则需要额外加上“--rotate”参数。
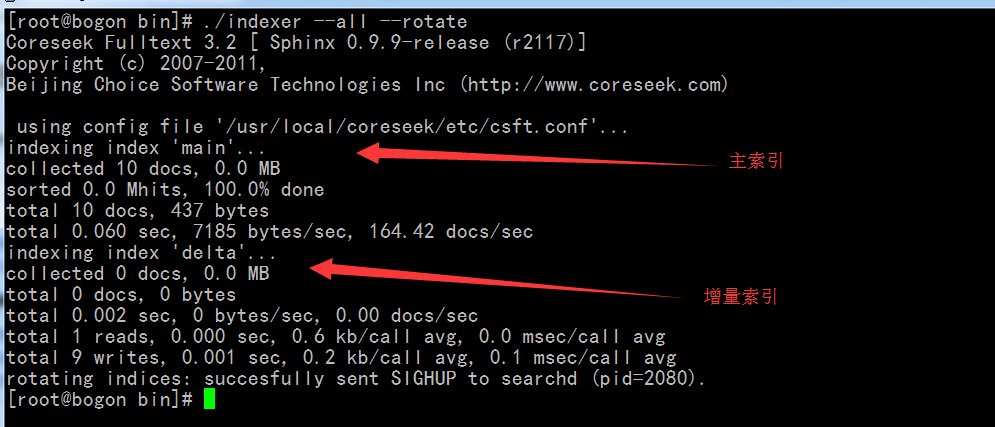
可以看出,索引源中已经多了delta。
三、实时索引执行策略
配置文件已经配置完成,接下来我们要配置它的实时执行策略。实现这个策略的原理也非常简单,那就是定时的进行增量索引的重新生成。
我们只需配置Crontab,关于Crontab的语法,这里就不再深究。这里我们只添加两条执行策略,分别是每天执行一次全索引(主索引)的重新构建,以及每十分钟执行一次的增量索引构建。以下是策略内容:

完成此配置之后,实时索引基本就完成了配置。
好的,本篇内容就先到这里,我们下一篇将继续讲述更多关于Sphinx/Coreseek的使用方法,我们下回见。
